
If you’re interested in the SEO of your online store, you’ve probably already heard about an important file located at the root of your site: the robots.txt file.
Essential for optimizing the path of search engine robots, it allows them to know which pages they can explore and which ones they can't.
Particularly useful on ecommerce sites that contain many dynamic URLs related to sorting filters, facets, or order pages, its configuration must be meticulous.
What is the robots.txt file?
As its name indicates, the robots.txt file is a text file located at the root of your site. It’s only intended for search engine robots.
It’s mainly used to indicate the different URLs of a site that aren’t allowed to be crawled.
Not being intended for internet users, it can prevent search engine robots from accessing part of the site, while leaving the latter accessible to visitors.
To find out if you have a robots.txt file on your site, simply type in your root domain and add “/robots.txt” to the end of the URL. If no page appears, you don’t have one.
Most of the time, it’s created by the webmaster or the site administrator, who will drag it into the directory provided on their FTP server. It can then be updated as many times as necessary.
If you use the WiziShop ecommerce solution, it’s automatically generated and configured. You’ll find an explanation of the different configurations present by default at the end of this article.
How does the robots.txt file work?
The two main missions of search engines are the following:
- to browse the entire web to discover content that’s being created all of the time and
- to correctly index this content so that it’s distributed in a relevant way to internet users looking for information.
To accomplish these tasks, search engine robots crawl billions of URLs on many websites.
The robots analyze the robots.txt file in order to identify crawling instructions. This is therefore content that the robots frequently look at.
They check for specific guidelines that may prohibit them, for example, from crawling certain pages or parts of the site.
Be careful, as the robots.txt file isn’t used to manage the indexing of your pages. It’s not intended for this purpose. If you have pages in your site that you don’t want to index, the noindex tag is more appropriate.
Concerning dynamic URLs, specific to ecommerce, that aren’t present in the basic structure of your site (faceted navigation, sorting filters, internal search engine, etc.), it’s good practice to prevent the various robots from visiting these pages.
What are the benefits of the robots.txt file?
As you’ll have understood, the integration of a robots.txt file on your website is often beneficial to facilitate exploration by search engine robots.
This file has many advantages and can become beneficial to your SEO.
Managing search engine robots’ crawling
The crawl is a key step in SEO. For a search engine, this notion represents the crawl of robots on the different URLs present on the Internet.
These crawled URLs can be HTML content, images, PDFs, JS and CSS files, and many others.
However, the resources of search engines aren’t unlimited. The popularity, the age, or the rhythm of publication of the site will determine the exploration time allocated for each site.
This exploration time is called the crawl budget.
The notion of crawl budget mainly concerns large sites with thousands of pages. If your site is smaller, the SEO issues related to this budget don’t concern you.
On the other hand, using the example of ecommerce, it’s possible that the site you have built and that you see as a user isn’t the same for the robots. Although your various faceted filters or sorting pages allow you to make the navigation of your visitors more fluid, it’s very likely that the robots see several thousand different pages.
In this case, the crawl budget can therefore come into play and have repercussions on your SEO because the robots will think, wrongly, that your site is too full of useless pages.It’s therefore important to crawl only relevant URLs to optimize the passage of robot.
The robots.txt file is particularly useful for preventing search engine bots from visiting pages that are of no interest. By configuring it efficiently, you’ll be able to anticipate these possible problems.
Avoid getting lost in the internal search engine
When you do internal searches on your site, it automatically generates URLs.
The pages of these internal search results often have no SEO interest and are endless. It may therefore be appropriate to block them, through your robots.txt file.
In this way, you prevent crawling by search engine robots.
Indicate the sitemap's URL
The sitemap is a file that lists all relevant URLs of a website.
The main purpose of the sitemap is to make it easier for search engine robots to navigate the site. Thanks to the sitemap, they can visit the pages of a site more easily.
To allow search engine robots to find your sitemap, you can add a link to it directly in your robots.txt file, in this form:
Sitemap: https://www.example.com/sitemap.xml
This can be useful for indicating the location of your sitemap to different search engines, but I recommend that you add it directly to your Google Search Console tool as well as to Bing Webmaster Tools.
Other uses of robots.txt
Some uses of robots.txt are quite common, even if its main function isn’t dedicated to these uses.
- Prevents visits to the administration area
The front office of a website refers to the part that is seen by internet users. In contrast, websites often have a back office, also known as an administration area. It is, in a way, the backstage of a CMS, that is to say the interface that allows the administrator to manage the website.
Of course, these pages are of no interest to internet users. Most CMSs will also block their crawling via the robots.txt file.
The best practice is to use password protection. This authentication prevents robots from accessing the site. This will also avoid disclosing your login URL to your administration area.
- Landing pages
If you frequently send newsletters to your customers and prospective customers, you’ll likely need to create all kinds of landing pages. These have essentially an advertising purpose.
They aim, for example, to present a particular event or a special offer. They have no real interest in terms of SEO. Once the event is over, these landing pages are often deleted.
Again, it may be tempting to add them in the robots.txt file. However, the best practice is to manage these pages via noindex tags. This is especially advantageous as when your competitors visit your robots.txt file, they can easily find your advertising pages.
- Duplicate pages
In general, duplicate content is detrimental to a website’s SEO. If crawlers see that your pages contain duplicate content, your ranking may drop.
A common practice is to manage duplicate pages via the robots.txt file to prevent search engines from crawling these URLs, but the noindex tag or the canonical tag may be more appropriate.
How do you test the robots.txt file?
Like any other part of a website, your robots.txt file must be tested to verify its efficiency. This allows you to detect possible configuration errors and to make corrections if necessary.
To test the efficiency of your robots.txt file, you can use the Google Search Console tool, available in the old version:

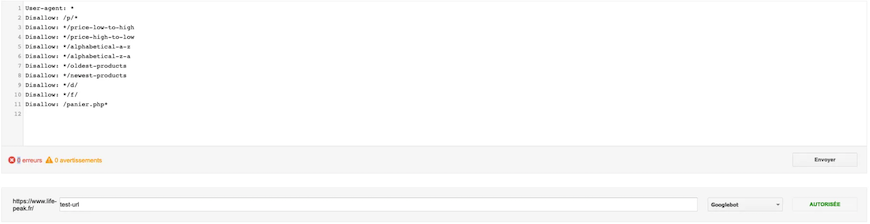
This allows you to test URLs to find out if they’re accessible or not. You just have to indicate it in the appropriate field to check if it’s blocked for Google.
Example with an authorized URL:
Example with a blocked URL:
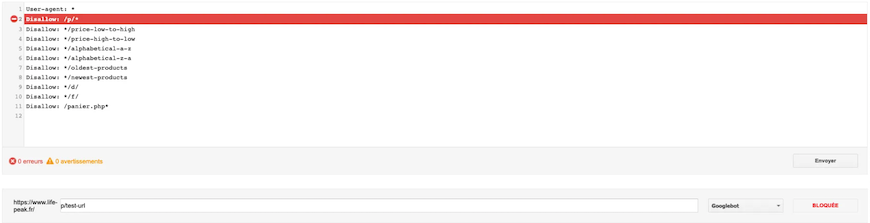
This type of testing is particularly useful to make sure that you’re not unintentionally blocking some of your relevant content or sections of your website.
If you wish, you can also use online tools like https://technicalseo.com/tools/robots-txt/.
Syntaxes of the robots.txt file
Several syntaxes are possible within the robots.txt file. Here are the most commonly used ones:
- User-agent: It allows you to specify to which crawler the instructions are addressed (example: Googlebot or Bingbot). Within the same file, you can specify different instructions for different user-agents.
- Disallow: This instruction indicates that the crawlers can’t crawl a URL or a folder.
- Allow: It indicates that crawlers can explore a URL even if it’s in a folder forbidden with a “Disallow.”
- Crawl-delay: It allows you to indicate the delay to be respected between the exploration of different URLs. This instruction isn’t taken into account by Google.
- Sitemap: This allows you to specify the location of the sitemap. It’s mainly used for other search engines because Google and Bing offer to add it directly in their webmaster tools.
The robots.txt on WiziShop stores
As I mentioned at the beginning of this article, the robots.txt file for WiziShop stores is generated automatically.
If you’re wondering what the different instructions are inside, here are the explanations:
User-agent: * \u2192 Concerns all search engine robots
Disallow: /p/* \u2192 URLs of customer accounts
Disallow: /panier.php* \u2192 URLs of shopping carts
To summarize, the default robots.txt configuration of WiziShop stores allows you to block the crawling of URLs related to customer accounts and shopping cart pages. This instruction is valid for all user-agents.
This file is accessible in your administration area. You can therefore add various configurations to block the crawling of the URLs of your choice.
The robots.txt file is effective but causes PageRank losses. That's why we are currently working on an alternative method to reduce and hide the links to these pages as much as possible.
WiziShop also gives you the ability to edit this file by adding specific instruction. However, this file is very sensitive, so only use it if you know what you’re doing!
Improper configuration can block the crawling of important URLs for your store and cause SEO issues.
In addition to other ecommerce SEO optimizations, the robots.txt file is an essential tool if you want to maintain control over the crawling of your online store’s pages. If no robots.txt file is created, all the URLs discovered by the robots will be crawled and end up in the search engine results.



![Keyword research tool: 11 of the best free and paid tools in 2026 [+ Bonus!]](https://wizishop.com/media/61db2a7e5bab8a085f2c7e8b/v1/keyword-research-tool-wizishop.jpg.webp)






