
The Google Search Console tool is essential for the vast majority of website publishers. Completely free, it’s particularly used to monitor the SEO performance of your online store.
One of the tool’s principle tabs is dedicated to the indexing of your site, and more precisely to the coverage. This part of Search Console allows you to have a precise vision of the crawl performed by Googlebot and of the indexation of your URLs.
You’ll be able to identify the pages of your site that Google has detected, crawled, and indexed as well as any problems encountered.
Unfortunately, for many people, this report can often be complex to analyze. Between the different errors and warnings that were reported or the exclusion of your pages, it can be difficult to find concrete solutions.
That’s why in this article, I’m going to present to you each element of this tab in detail.
Depending on the display of your Search Console, go directly to the dedicated point in this article to understand and analyze it more effectively (the CMD+F or CTRL+F commands can save you time).
This article will also be updated based on the feedback of our e-merchants to include as many examples and practical cases as possible.
Don’t hesitate to share your feedback in comments—we’ll quote you in the article to highlight your solutions!
The index coverage report
First of all, when you click on the “Coverage” tab, the first thing that you’ll see is the summary of the indexing status of your site’s different URLs that Google knows about.
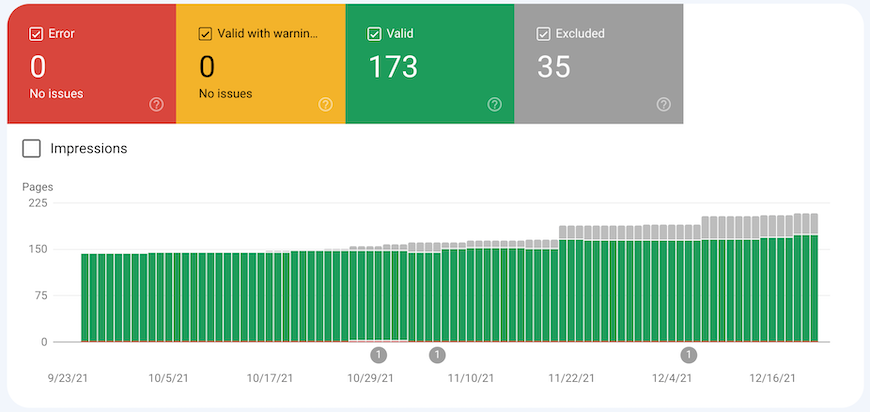
In this summary, you have the following:
- Error: the page couldn’t be indexed. It doesn’t appear in the search results.
- Valid with warnings: the page is indexed but has some problems to analyze.
- Valid: the page is indexed. It may appear in the search results.
- Excluded: the page isn’t indexed because Google has followed the configuration of your site and has concluded that it should be excluded from the index.
As a WiziShop e-merchant, it’s quite possible that your graph may have many pages in the “excluded” section.
Since a merchant site has many non-indexable URLs related to faceted filters, sorting filters or shopping cart pages, this is normal.
Then, for each of the points mentioned above, you can analyze the information more precisely when you go down the page.
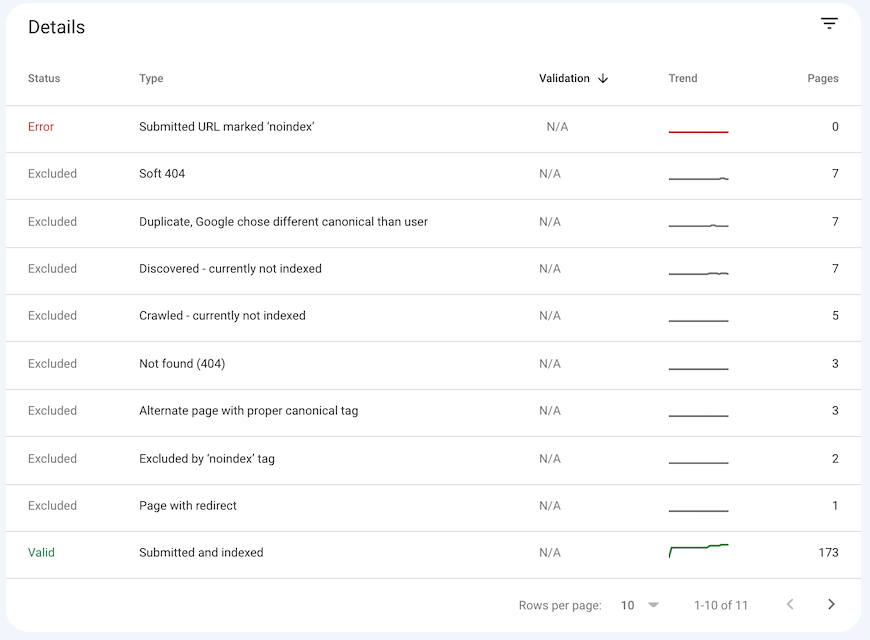
I’ll explain each of the bits of information just a little further down in the article.
The “error” report is the most important. This is the one you should analyze first to correct any problems on your site that prevent the indexing of your pages.
Now that you have a better understanding of this summary, it’s now time to go into a little more detail and explain the different errors, warnings, and reasons for exclusion that can be displayed in the tool.
Search Console errors
As a reminder, the pages that are displayed in error are pages that could not be indexed by Google. They can’t be referenced in the search engine.
You must then click on the error to identify the URLs concerned.
Here are the different reasons that can cause these errors and non-indexing problems.
Server error (5xx)
When Googlebot visited the site, the server returned a 500 error, which prevented Google from crawling the URL.
These errors are mostly temporary. During the robot’s crawl, the server could have been unavailable, overloaded, or misconfigured.
Solution:
To correct the server error, you just have to check that the URL is accessible again and then launch a validation of the correction.
If the error persists, consider contacting your developers or your web host.
If you’re a WiziShop e-merchant, you should know that we take care of all these technical aspects for you. Our teams react very quickly to this type of problem.
Redirect error
When Googlebot visited your URL, it encountered one of these redirection errors:
- Redirect chain that’s too long
- Redirect loop
- The redirect URL exceeded the maximum URL length
- Redirect chain with incorrect URL
This type of error is quite common in ecommerce. It’s often caused by product and category deletions.
For example, you may have created redirect chains:
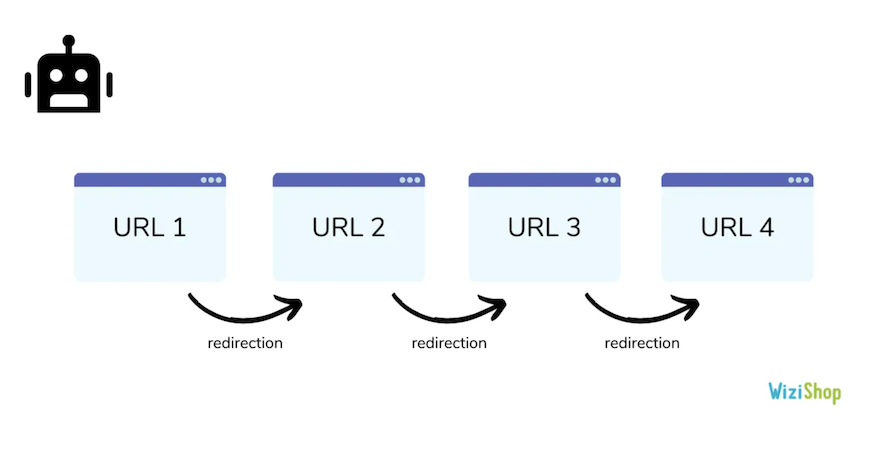
These misconfigurations can occur when you delete a product and add a redirect to a new product. Then, a few months later, you delete that product and add a redirect to a new one. And so on. The old redirects will stay and cause a chain.
The best practice is to make it so that
- URL 1 redirects to URL 4
- URL 2 redirects to URL 4
- URL 3 redirects to URL 4
Another case encountered is that of redirection loops:
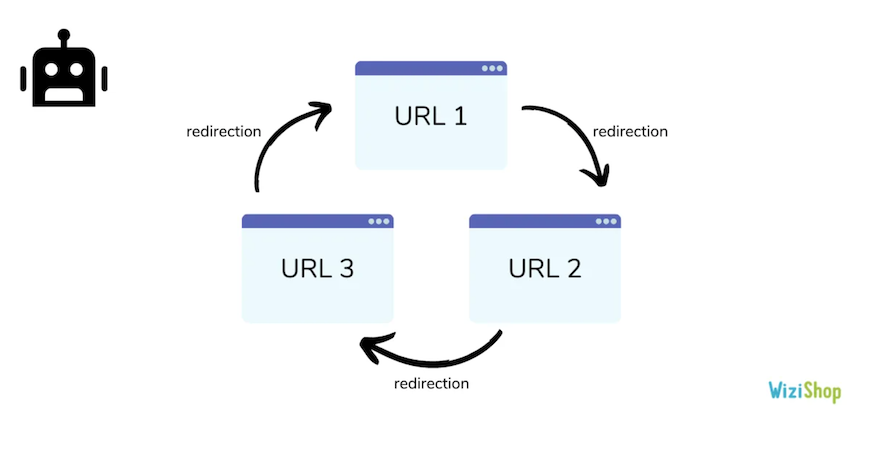
The best practice is to have a final page that responds well in code 200 and to redirect all URLs directly to it.
All these bad redirection configurations will come up as errors in your report.
Solution:
You must analyze each of your redirections to configure them correctly in order to avoid chains, loops, and other errors. Each URL should only perform one redirection.
As a WiziShop platform user, you can easily analyze them by going to “General Preferences > Manage Redirections.”
Complementary resource: https://wizishop.com/blog/301-redirect
Submitted URL blocked by robots.txt
This error means that you’ve submitted a URL, via your sitemap, but it’s blocked in your robots.txt file. Depending on the settings you’ve added in your robots.txt file, this may prevent the crawling of some URLs or directories of your site.
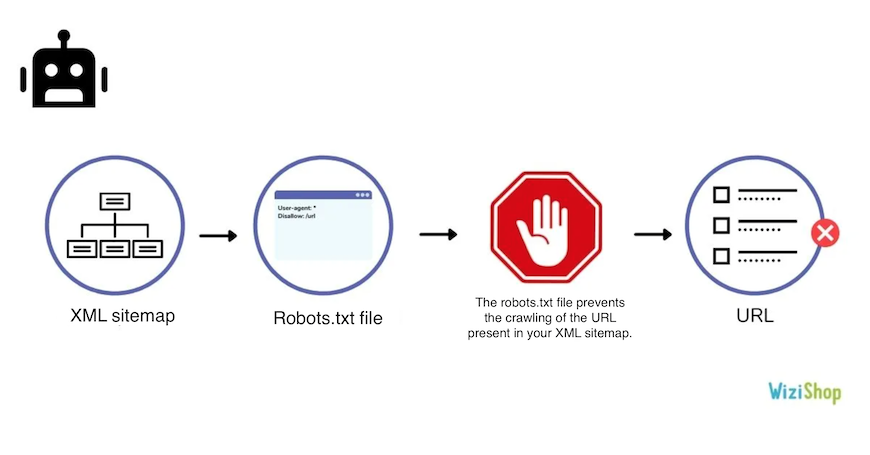
Solution:
If the URLs should be crawled, make sure to remove the directive in the robots.txt file. Otherwise, if the URL shouldn’t be accessible, remove it from your sitemap file.
You can also use the tool proposed by Google to test your URLs: https://support.google.com/webmasters/answer/6062598?hl=en
As a WiziShop user, everything is technically optimized at this level: the robots.txt file is automatically generated and contains only URLs that shouldn’t be crawled. By default, no URL of your sitemap can be blocked by your robots.txt file.
Complementary resources: https://wizishop.com/blog/robots-txt and https://wizishop.com/blog/sitemap
Submitted URL marked “Noindex”
This error indicates that you are sending URLs via your sitemap file but they contain the noindex directive. This noindex tag may be in the source code or in the HTTP header.
Solution:
Again, if the URLs concerned must be indexed, remove the noindex. On the other hand, if they shouldn’t be indexed, remove them from the sitemap file.
On WiziShop, each page that you indicate in noindex will automatically not be included in the sitemap file to prevent this error.
Complementary resource: https://wizishop.com/blog/noindex
Submitted URL seems to be a “Soft 404” error
A soft 404 error is represented by a URL that responds in code 200 but displays a 404 page or looks like a 404 (no content).
For example, in ecommerce, a category with no product can go up in this section.
When Googlebot goes to the URL, it’ll come across a page that’s accessible, without content or product, which has the appearance of a 404 page:

This error will appear here if you have URLs of this type in your sitemap file.
Solution:
To correct this problem, in the case where the URL must display a 404, you must configure the HTTP code. Then, delete it from your sitemap file.
If this URL must be indexed, optimize it in order to prevent it from having aspects of a 404 page by adding unique and relevant content.
Submitted URL returns unauthorized request (401)
Your sitemap file contains URLs with a 401 response code. This HTTP code means that the access is unauthorized.
The HTTP 401 code is typically for test and pre-production site environments that require logins and passwords to log in.
Solution:
In case the page needs to be blocked and accessed via authentication, make sure to remove it from your sitemap file. Otherwise, you must allow Google to access it by removing the authentication.
Submitted URL not found (404)
Your sitemap file contains URLs that don’t exist on your site (404).
Solution:
If your page doesn’t exist, consider removing it from your sitemap file. Also check that no link points to this page.
It’s also possible that this page has been deleted by mistake. If this is the case, restore the content of the page and validate the correction.
Submitted URL returned 403
This case is quite similar to the 401 error. The difference is that the HTTP code 403 means that the server forbids access to this URL. No authentication is possible.
Solution:
As with the 401 code, if these URLs should deny access to web users, remove them from the sitemap file. Otherwise, make sure to display a suitable HTTP code.
URL blocked due to another 4xx problem
Your sitemap file contains URLs that return different response codes than the 401, 403, and 404.
Solution:
Check the different URLs as well as the associated error codes. Analyze the problems and correct them.
As for the previous ones, if the URLs in error shouldn’t be detected, delete them from your sitemap file.
For all these errors, once the problem is corrected, the “Validate Fix” button allows you to inform Google of your changes.
It will then send you an email to let you know if the problem is corrected or if it persists.
Search Console warnings
Next to the errors, you’ll find the section entitled “Valid with warnings.”
Only two types of warnings can be found in this tab.
Indexed, though blocked by robots.txt
This warning means that Google has decided to index URLs that are blocked in the robots.txt file.
As a reminder, the robots.txt file makes it possible to prevent the crawling of URLs but not the indexing.
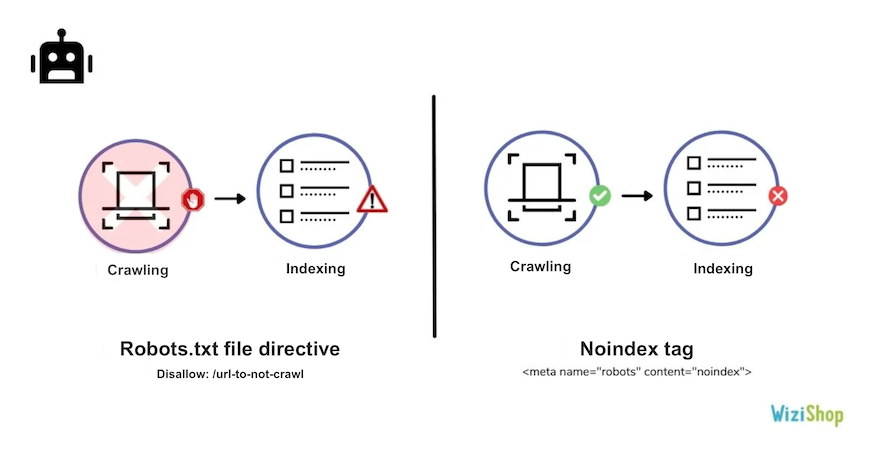
This means that if Google identifies links pointing to these blocked URLs, it can decide to index them, without even exploring them.
This is a problem that has been reported by many of our e-merchants:
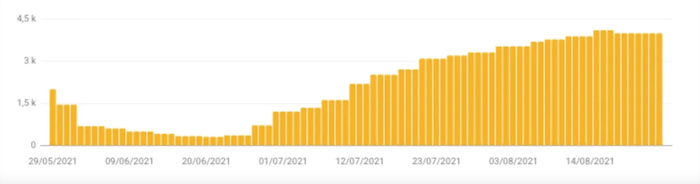
Example n°1: 3,980 URLs indexed, though blocked by the robots.txt file
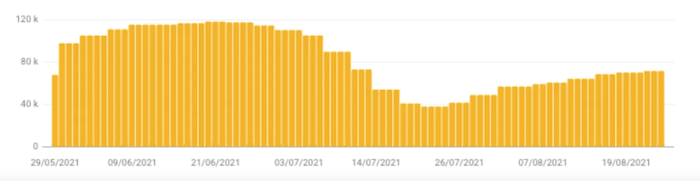
Example n°2: 70,800 URLs indexed, though blocked by the robots.txt file
On WiziShop, the URLs generated by the filters have, by default, a noindex tag. To reinforce this blocking and to optimize the crawl budget, we also decided to block the crawl in the robots.txt file.
The problem is that Google has detected the different links to the filters in the internal mesh and has decided to index them. Since it doesn't actually crawl them, it doesn't detect the noindex tag.
Solution:
If they should be crawled, remove the directive from your robots.txt file.
If they should not be crawled, I remind you that blocking by robots.txt prevents Google from crawling your pages and therefore from detecting the noindex tag. These warnings cannot be corrected by themselves. If you want to de-index the indexed URLs, here is the method:
1. Add or check that a noindex tag is present on all pages that should not be indexed
2. Remove the directives from the robots.txt file so that Google can crawl your URLs and understand that these pages have a noindex tag (Google explains in its documentation that robots.txt is not the right way. It is rather recommended to use the noindex tag)
3. Wait until the report “Indexed, though blocked by robots.txt” drops to 0
4.a. If you have a small or medium size site, with a few thousand non-indexable URLs, you can keep this configuration
4.b. If you have a site with several hundred thousand URLs, the question of the crawl budget comes into play. When you make a very large number of URLs accessible, it's important to optimize the efficiency of the crawl. In this case, it's recommended to make the different internal links pointing to these pages inaccessible for Google via the use of Javascript / Ajax or obfuscation techniques.
When you can and when the type of URL allows it, I also advise you to opt for blocking via authentication if these URLs concern unauthorized directories.
Solution on WiziShop:
Of course, the noindex tag remains on each generated page to avoid indexing in case the search engine detects and crawls them.
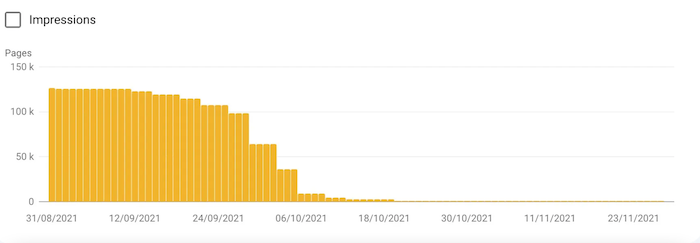
Example n°1: From 130,000 pages indexed, though blocked by the robots.txt file to 108
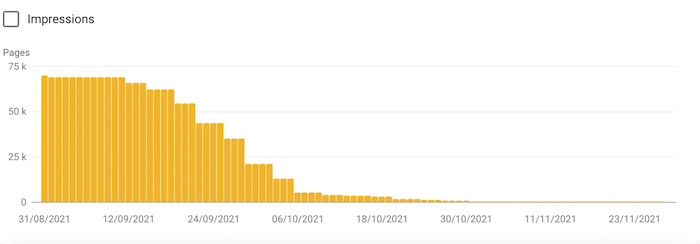
Example n°2: From 70,000 pages indexed, though blocked by the robots.txt file to 63
All these pages have moved to the excluded pages report, at the level of “Excluded by noindex tag.”
Our analysis has shown that following this removal of the parameters in the robots.txt file, no store has suffered any SEO loss.
If you have a site with tens of thousands of URLs, I invite you to check the path of googlebot on your site with our partner Seolyzer.
This log analysis tool allows you to directly track the URLs visited by googlebot and identify the time spent on the different sections of your site. You can therefore have an accurate view of your filters and know whether or not they are causing problems.
Complementary resource: https://wizishop.com/blog/seolyzer
Based on your analysis, I remind you that via a specific development, you can obfuscate the internal links to the facet filters on your WiziShop store. HTML customization or FTP access give you the possibility to make these modifications.
Indexed without content
This warning means that Google has indexed some of your site's URLs, but for various reasons, it cannot read the content: cloaking, unsupported format, etc.
Solution:
Retrieve the URLs and use the search console's URL inspection tool to analyze what Google sees and apply corrections.
Valid
The Valid URLs report contains all pages indexed by the search engine. There are two types of valid pages.
Submitted and indexed
The URLs displayed here are all the ones you’ve submitted via a sitemap file and that are indexed.
Solution:
No action to take
For an ecommerce site that frequently adds products and writes blog posts, the ratio of valid indexed pages should gradually increase over time.
Indexed, not submitted in sitemap
The search engine has indexed URLs of your site that aren’t present in your sitemap file.
Solution:
In the case where these URLs must be indexed, think of adding them in your sitemap file.
On the other hand, if they should not be indexed, add a noindex directive or apply other blocking methods adapted to your site.
Excluded
Finally, the last tab that you'll find in your coverage report is the excluded pages. These are the pages that aren't indexed on your site.
The information and data displayed here are very helpful to analyze possible technical problems on your website or indexing issues.
Excluded by the “noindex” tag
These URLs are excluded from indexing because they contain a noindex directive (in the HTML or in the HTTP header).
Solution:
If the URLs listed here should not be indexed, you don’t have to take any action. The only advice I can give you is to reduce the internal links to these pages as much as possible to avoid sending too much SEO juice to these non-indexed pages.
As seen before, as a WiziShop e-merchant, you will find in this section the filter pages or the internal search engine pages. You don’t have to make any corrections on your side.I
In case these pages need to be indexed, you have to remove the noindex tag.
Blocked by page removal tool
Search Console offers a tool for removing URLs from its index. If you’ve used it to remove URLs, they won’t be indexable for a period of 90 days.
After this period, Google will be able to index these URLs again.
Solution:
The URL removal tool isn’t a viable long-term solution to prevent the indexing of certain pages on your site. It’s recommended to use the noindex tag instead.
Blocked by robots.txt
The robots.txt file allows you to prevent the crawling of certain URLs.
Solution:
If the URLs blocked in your robots.txt file aren’t important, no action is required. Be careful, as you’ve seen before, this doesn’t mean that the page won’t be indexed.
In case some blocked URLs need to be crawled, you’ll have to remove the directive in the robots.txt file.
Blocked due to unauthorized request (401)
As seen above, the 401 code means that Google hasn’t received permission to access these URLs.
Solution:
First, check that these URLs should be inaccessible to Google.
While analyzing these URLs, if you detect sensitive directories, try to find out how Google came across them. It’s possible that internal or external links point to these URLs.
Crawled, currently not indexed
Due to the increasingly frequent indexing problems on the internet, it’s quite possible that URLs from your site are coming up in this section.
“Crawled, currently not indexed” means that Google has crawled your URL but has not yet indexed it.
Several reasons can be the cause:
- Google has just discovered the page and will soon index it
- Google has determined that this URL is not relevant enough to be indexed: weak or poor-quality content, duplicate content, page depth, etc.
Solution:
If your URL has just been published recently, wait before drawing any conclusions.
If your URL has been in this report for several weeks, you’ll have to analyze your page to find ways to improve it (analysis of the search intent, content improvement, internal links addition, etc.).
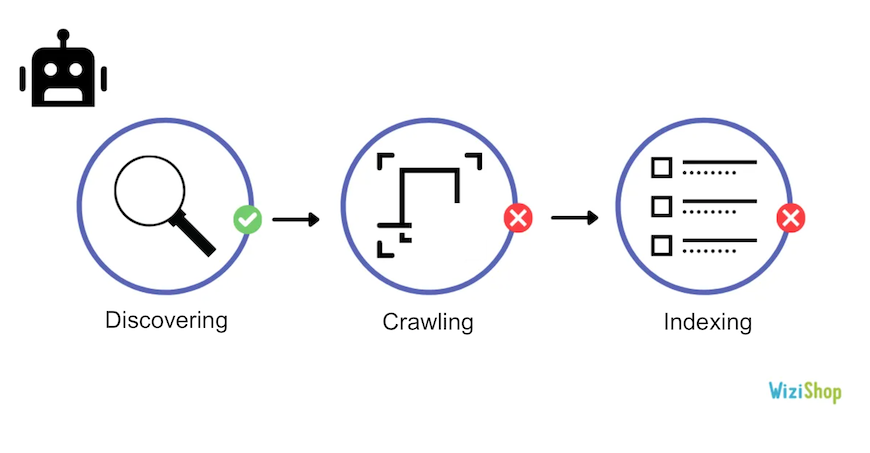
Discovered, currently not indexed
The URLs that come up here are those that Google has detected but not yet crawled. They have been added to the queue and will be crawled soon.
This is often due to the fact that Google has postponed crawling because of website overload or simply because it hasn’t had time to crawl them yet.
Be careful…another reason may be related to the fact that Google considers that the overall quality of your site is low. It’ll therefore take much more time to explore the new pages.
Solution:
In most cases, you just have to wait for Google to crawl the different URLs. If you’ve just launched your site, you’ll encounter many URLs in this report, so you should be patient.
If you find that many URLs are added to this report and they’re never crawled after some time, it’s possible that bots are experiencing some problems while crawling your site. You can use the log analysis and check, for example, that your site doesn’t contain any bot traps (filters, misconfigured plugins, etc).
This can also be caused by the low quality of your content. In this case, you should rework and improve your pages.
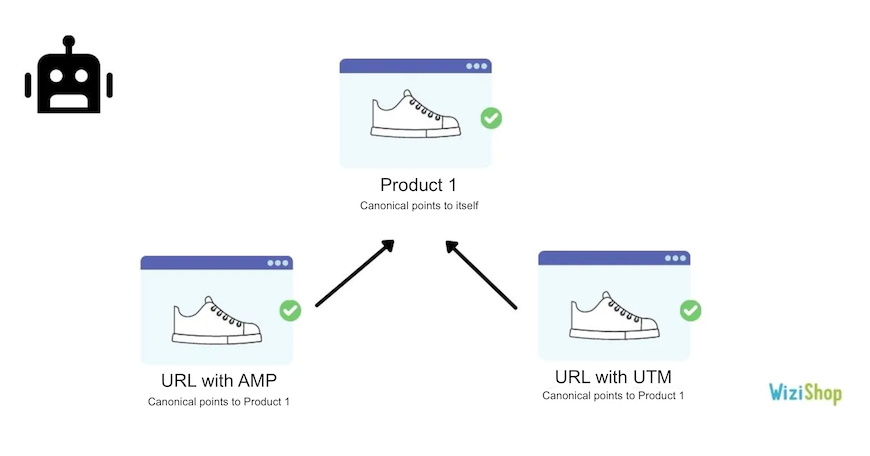
Alternate page with proper canonical tag
Google lists here the URLs that have a canonical URL to another page, correctly selected by Google as the main page.
Solution:
If these URLs are indeed duplicate pages that should not be indexed, you don’t have to take any action.
On the other hand, if the analyzed URLs aren’t duplicated pages and must be indexed, you need to modify the canonical tag to make it point to itself.
As a WiziShop e-merchant, the URLs that will stand out here are those related to AMP (if you’ve activated it). You can also have affiliate URLs or UTMs.
Complementary resource: https://wizishop.com/blog/canonical-url
Duplicate without user-selected canonical
Google has identified these URLs as duplicates. No canonical URL is specified. The search engine has therefore excluded them.
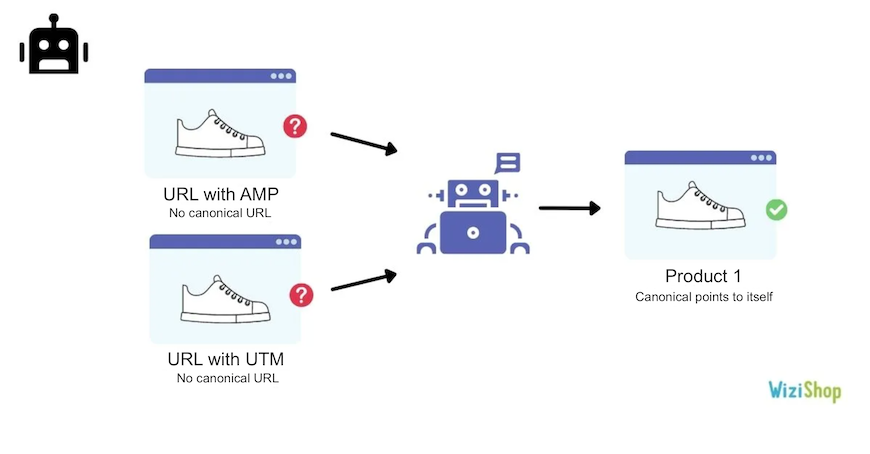
By adding the URL in the URL inspector, you can analyze the URL selected by Google as canonical.
Solution:
You should add canonical URLs on each of your pages to show clear guidelines to Google. In this case, specify the canonical URL to point to the main page.
If you don’t want these URLs to be referenced and indexed, opt to add a noindex tag instead. If you don’t want them to exist at all, you can also remove them (while making sure that no links point to them).
Duplicate, Google chose different canonical than user
In this section, Google will show you the URLs that contain a canonical URL but are, for Google, not relevant to be canonical. It therefore selects another canonical URL to index.
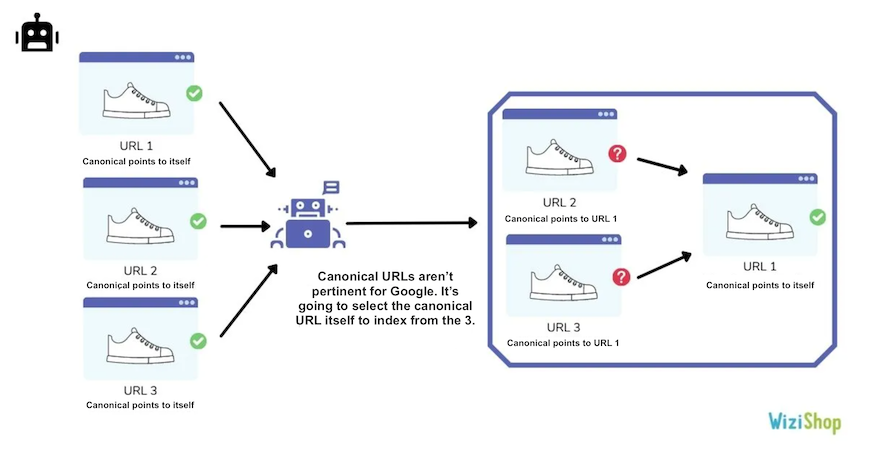
This often happens when your website contains pages with little content that are quite similar to other URLs.
Solution:
Again, you can use the URL inspection tool to find out which URL Google has deemed more relevant to index and make canonical. If it makes sense, set the canonical URL to the one recommended by Google.
If it doesn’t, you’ll have to rework your page to make it more unique.
Not found (404)
The URLs listed here returned a 404 error during Googlebot’s crawl. These URLs aren’t present in the sitemaps, but the search engine detected them.
It’s possible that these are pages that existed in the past or URLs that have links from other sites.
Solution:
In case these URLs should indeed display a 404 code and they’ve recently been removed, Google will continue to try to access them for a while and then forget about the URL. If the 404 is intentional, this isn’t a problem.
However, you should check that no more links point to this URL. If external links point to this one, it may be beneficial to set up a 301 redirect to another similar and relevant URL.
If these are important URLs that shouldn’t be deleted, it’s important to correct this error and restore your content.
Also remember to check the date the URL was crawled. It’s possible that it hasn’t been crawled for several months.
Page with redirect
URLs are redirects, so they’re excluded from the index.
Solution:
In most cases, you don’t have to correct anything here, except to check that the URLs with redirects are correct.
Soft 404
As seen before, soft 404 corresponds to URLs that don’t display a 404 code but strongly resemble a 404 page.
Solution:
For URLs that are indeed 404, you need to set up a 404 response code.
If they’re not supposed to be 404, you’ll have to rework the content of the page to make it relevant and qualitative.
Duplicate, submitted URL not selected as canonical
This section is similar to the “Duplicate, Google chose different canonical than user” case. The difference here is that you submitted the URL via a sitemap file.
The URLs present here are therefore in your sitemap file and Google has deemed it more relevant to index another one.
Solution:
Since the URLs are present in the sitemap, it's important to check each of them.
If the URL concerned is a duplicated page that shouldn’t be indexed, remove it from your sitemap file and point the canonical URL to the relevant version.
In the case where the URL is not a duplicated page but a unique page, it’s important to rework its content to make it unique.
Blocked due to access forbidden (403)
The concerned URLs could not be visited because Google has a ban on accessing them.
Solution:
If the URLs must be excluded from the index, it’s preferable to apply a noindex tag or to block the exploration via the robots.txt file.
In case the URLs should be crawled and indexed, allow access by displaying an HTTP 200 code.
Blocked due to other 4xx issue
When Google tried to access these URLs, it encountered 4XX response codes, different from 401, 403, and 404.
Solution:
Analyze the URLs with the Search Console inspector to identify the HTTP code.
If the URLs are significant, fix the problem to ensure that the URL can index properly.
If not, check that no links point to these URLs and implement a suitable block.
To conclude this article, you’ll have understood that it’s crucial to configure your Search Console to follow this report carefully and check the health of your online store.
As soon as errors appear on your site, you’ll receive an alert by email and can react quickly.
Of course, even though Google Search Console (formerly Google Webmaster Tools) is a tool provided by Google, it can occur that some information comes back with a delay or that you encounter erroneous data. It’s therefore important to always take your time to analyze the different elements and use the features at your disposal.
Don’t forget to add your feedback in the comments so that we can get as much feedback as possible on the different cases mentioned above!


![Keyword research tool: 11 of the best free and paid tools in 2026 [+ Bonus!]](https://wizishop.com/media/61db2a7e5bab8a085f2c7e8b/v1/keyword-research-tool-wizishop.jpg.webp)







Faculty of Economics and Management le 16 April 2026 à 12:34