
To display relevant results to internet users and prevent search engine bots from showing pages that aren’t beneficial for SEO, you need to manage your site’s indexing intelligently.
On your online store, you may not want one or more of your pages to be indexed. If this is the case, it’s high time to use the noindex tag! Don’t know what this SEO tag is all about? Here’s a complete guide to introduce you to it, explain how to insert it on your pages, and describe the various types of content for which it’s appropriate to use it.
What is the noindex tag?
It’s a tag that informs search engines that a page shouldn’t be indexed or displayed in the results. It’s usually found in the source code of the page, within the <head> section.
To provide additional guidance to search engines when they arrive at these pages, it can be supplemented with other attributes like “follow” or “nofollow.” I’ll introduce these additional guidelines later in the article.
How do you add a noindex tag to your page?
The integration is quite simple. It can be included directly in the HTML of the page or in the HTTP header. It’s up to you to define which one is the most adapted for your site.
Page header
To integrate the tag, it’s necessary to have access to the source code of the page in question.
Once you’re in the page’s code, complete the following steps:
- Look for the <head> section of your page.
- Embed the following tag: <meta name="robots" content="noindex">.
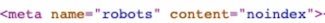
The tag shown above has a standard format. However, it’s possible to include directives that are even more specific.
This can be the case if you only want to prevent Google from indexing the page on your site.
In this situation, simply replace the term “robots” with the name of the relevant robot. For example: <meta name="googlebot" content="DIRECTIVE">.
Note that it’s also possible to include several directives one after the other. Simply separate them with a semicolon.
HTTP header
If you want to prevent the indexing of a page of your site, note that it’s also possible to do so via the HTTP header. This is the information that’s directly sent by the server.
The x-robots-tag is included directly in the HTTP header and allows you to control the indexing of the page. It is presented in this form:
HTTP/1.1 200 OK
(...)
X-Robots-Tag: noindex
(...)
Particularly useful when it comes to PDF, Powerpoint, Word, etc. documents that don’t contain HTML code, this tag is added directly to the HTTP header of the page.
Follow and nofollow directives
As mentioned earlier, the noindex tag can be followed by directives like follow and nofollow.
The nofollow indicates to the robots that they shouldn’t follow the links in the page. As a consequence, all the links on the page won’t be followed by the robots.
This element is added in this way:
<meta name="robots" content="noindex, nofollow">
On the other hand, the follow stipulates to robots that they can follow the links in the page.
However, its use is rather controversial since, by default, the search engine follows the links present on the page if you don’t specify any indication. This value is therefore somewhat useless.
Another piece of information that calls into question its effectiveness is that John Mueller himself announced that a page that has been noindexed for some time can be treated as a 404 error. This means that it’ll be crawled much less by the robots, and the links will therefore be followed much less.
If you insist on using it, however, it will appear in this form:
<meta name="robots" content="noindex, follow">
There are also other guidelines that you can find directly in the Google documentation.
On which types of pages should you add a noindex tag to optimize your SEO?
When they arrive on a site, search engine crawlers visit all the pages (unless indicated in the robots.txt file).
If no indexing directive is stipulated, they’ll index the entire site.
In ecommerce, it’s common to have various pages that don’t have much interest when it comes to SEO. Between the filters, the internal search engine, or the customer account URLs, your store can quickly end up with a large number of low-quality pages.
By making all of these pages indexable, search engines will take them into account when analyzing your site. This can cause significant SEO problems.
They can affect the overall rating of your site and therefore your ranking in search results.
For this reason, it's better to index fewer pages and limit yourself to really relevant content. In this case, the noindex tag is ideal to prevent the indexing of certain sections of your website.
Internal search engine
The internal search engine of a site refers to the search bar that’s featured inside the site in question.
It’s essentially used by internet users so that they can more easily access the information or products that they’re looking for.
It’s very useful and creates loyalty for your visitors, and it’s frequently used on ecommerce sites. It greatly facilitates the purchase of products and helps the visitor to find a solution to their request.
On the other hand, in terms of SEO, the pages that are specific to it are of no particular interest. It’s therefore better to make this part of the site non-indexable.
Poor or duplicated content
As you probably know, Google is always looking for quality to provide to its users.
For this reason, the search engine hates duplicated content and low-quality pages.
If you have an online store, these pages with poor content will be represented by the sorting filters, the faceted navigation, the shopping cart page, etc.
Concerning duplicate content, adding the noindex can be a good idea to avoid SEO problems, but I advise you to use the canonical tag in these cases.
PDF files
Sometimes your site may also include PDF files.
These files may be of little interest in terms of SEO. Moreover, they can also be
copyrighted content or white papers intended only for your customers or prospective customers.
In this case, they shouldn’t be indexed. The use of a tag is therefore relevant.
Be careful, however, since these are documents without HTML, you can’t add the noindex tag in the <head> section. You’ll have to resort to adding a directive in the HTTP header of the page.
Login and customer account
Finally, as there’s no need to index the pages of the internal search engine of the site, it’s also not wise to show the pages related to customer accounts (login page, forgotten password, account creation,...).
They allow regular users of your website to log in and find all their internal information.
However, other internet users have no interest in accessing them directly. The login and customer account pages can therefore have a noindex tag.
Noindex pages on WiziShop stores
To tell you a little more about the configuration on the WiziShop CMS, all the types of pages presented above automatically have a noindex tag.
In order to optimize the indexation of your site and therefore your SEO, all the pages of low quality and without interest for the robots are not indexable: sorting URLs, faceted navigation, customer accounts, internal search engine, etc.
If you wish, you can also add a noindex tag on free pages. Just drag the slider to the left.

Difference between noindex tag and robots.txt file?
Often confused, it doesn’t have the same function as the robots.txt file.
The noindex tag provides instructions to the robots when they consult a page of the site.
It makes it possible to define if a page should be indexed or not. The robots can therefore still consult it and explore it.
The robots.txt file, on the other hand, allows you to tell the robots if they have the right to access a page. It makes it possible to define if a page shouldn’t be explored. The robots can therefore not even consult it.
I invite you to read our full article on the robots.txt file as well as the one on the sitemap to learn more about how to optimize search engine robots’ crawling of your site.
The use of a noindex tag should be carefully considered. Since this tag indicates to the robots that a page shouldn’t be indexed, an error in the directive can cause SEO problems, especially if they’re strategic pages!
By using it wisely, it remains particularly effective in informing search engines of pages of no SEO interest and preventing indexing, which can harm the overall health of your site.



![Keyword research tool: 11 of the best free and paid tools in 2026 [+ Bonus!]](https://wizishop.com/media/61db2a7e5bab8a085f2c7e8b/v1/keyword-research-tool-wizishop.jpg.webp)






